GetPaper v2.0
基于Sci-Hub的文献下载器,输入关键词后即可在指定数据库中爬取所需文献。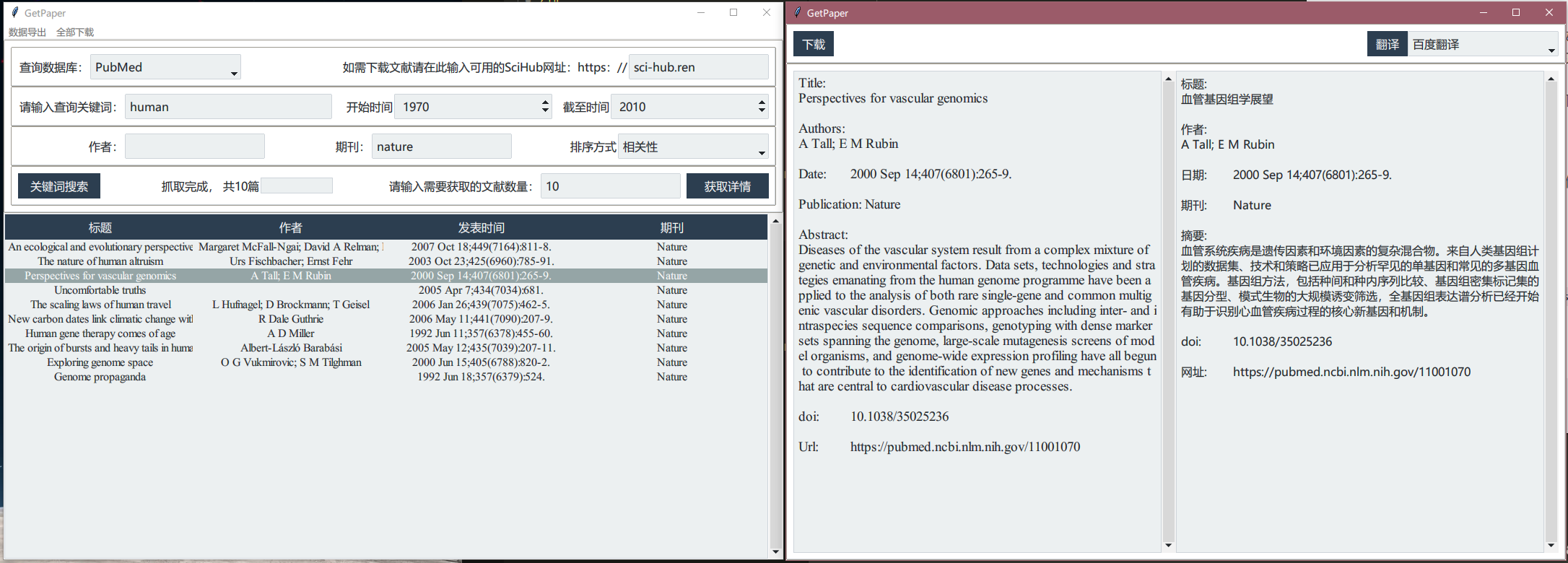
- 使用ttk.bootstrap重新设计GUI,增加作者、期刊、日期、排序方式选项
- 使用基于协程的爬虫引擎提高文章爬取速度,同时使用多线程避免GUI线程阻塞问题
- 增加爬虫引擎接口,可添加其他数据库爬虫。目前已有ACS和PubMed爬虫引擎。
- 增加翻译功能接口,可添加其他的翻译源,目前使用的是百度翻译Api。
- 通过Sci-Hub下载指定文献或所有爬取结果的pdf
运行方法
项目已打包为exe文件,下载后可直接使用。
运行环境:python3.8+
- 克隆本项目后cd至项目目录
- 使用
pip install -r requirements.txt python main.pyw运行项目- 如需打包,运行
pyinstaller main.spec,main.spec已配置好相关静态文件。
翻译功能需要自行注册百度翻译Api后将个人
appid与key添加到api_info.json中。exe可直接使用翻译。
使用方法
- 选择需要查询的数据库
- 输入查询关键词(必选)以及其他搜索条件(PubMed搜索需要同时输入开始时间和截至时间后,搜索时间才会生效)
- 点击
关键词搜索爬取文献数量信息后,输入需要获取的文献数量,点击获取详情开始爬取文献标题、作者、期刊等信息。不建议在不清楚文献搜索结果总数时直接点击获取详情,如果获取数量大于搜索结果数量会等待至Timeout后结束任务 - 双击搜索结果打开详情页,点击
翻译按钮对文献标题和摘要内容进行翻译,点击下载按钮将从Sci-Hub下载本文献的pdf - 主界面的
全部下载用于从Sci-Hub下载搜索结果中的所有文献的pdf文件,如下载失败会生成对应的txt文件。为避免对其服务器造成过大压力,已限制下载频率。 - 主界面的
导出数据用于将搜索结果导出为csv文件,可使用excel另存为xls或xlsx
项目结构
├─getpaper |
爬虫引擎接口
在
getpaper/spiders内添加name.py文件后能够被自动识别并在GUI中显示,如需打包为exe文件,则必须在getpaper/config.py中if hasattr(sys, "frozen")时spider_list中添加对应的<name>,否则打包后无法识别动态导入的模块。类名必须为
Spider且继承getpapaer._spiders中的_Spider基类,用于检测爬虫是否实现了以下方法:- 初始化爬虫时调用的方法,用于接受GUI传入的搜索相关条目,进行解析后用于搜索,其中
sorting为搜索结果,包括”相关性”, “日期”, “日期逆序”。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class _Spider(ABC):
def __init__(self, keyword: str = "",
start_year: str = "",
end_year: str = "",
author: str = "",
journal: str = "",
sorting: str = "") -> None:
"""
Base spider
Args:
keyword: keyword, split by space
start_year: default to 1900
end_year: default to next year
author: filter by author, default to None
journal: filter by published journal, default to None
sorting: sorting result by details or match
"""
self.data = self.parseData(keyword, start_year, end_year, author, journal, sorting)
def parseData(self, keyword: str,
start_year: str = "",
end_year: str = "",
author: str = "",
journal: str = "",
sorting: str = "") -> Dict[str, Any]:- 根据搜索信息对数据库进行查找,并返回找到的文献数量提示信息,返回的字符串用于在GUI显示。
def getTotalPaperNum(self) -> str:
"""
Get the total number of result
Returns:
num: number of search result
"""
pass- 获取
num篇文献的标题、作者、发表时间、发表期刊、摘要、doi号、网址,并将结果保存至queue中,该队列还用于监控当前的下载进度。
def getAllPapers(self, queue: PriorityQueue, num: int) -> None:
"""
Get all papers detail
Params:
queue: a process queue for storing result and feedbacking progess,
details format is [index, (title, authors, date, publication, abstract, doi, web)]
num: number of papers to get
"""
pass数据保存顺序参考如下,不得更改顺序。其中index为文献的序号,用于按序输出搜索结果。
queue.put(index, (title, authors, date, publication, abstract, doi, web))
- 初始化爬虫时调用的方法,用于接受GUI传入的搜索相关条目,进行解析后用于搜索,其中
翻译引擎接口
在
getpaper/translator内添加name.py文件后能够被自动识别并在GUI中显示,如需打包为exe文件,则必须在getpaper/config.py中if hasattr(sys, "frozen")时translator_list中添加对应的<name>,否则打包后无法识别动态导入的模块。类名必须为
Translator,用于动态导入该模块api相关数据保存在
getpaper/translator/_api_info.json中,推荐使用以下方法读取该json文件,该方法能够在打包后正常读取文件。
f = importlib.resources.open_text('getpaper.translator', '_api_info.json') |
- 实现
translate(self, detail: str) -> str方法,文章的title和abstract会分别调用此方法进行翻译,返回的字符串会通过str()转换后显示到文本框内。
其他
使用协程函数:使用
getpaper.utils中的@AsyncFunc对主协程函数进行装饰,才可以被正常调用。异常处理:捕获异常后使用
getpaper.utils中的TipException(tip),通过唤起该异常可以在GUI中显示对应的tip信息,不超过16个字符(8个汉字)。如果异常导致爬取任务中断,建议使用数据将queue填满或修改queue.max_size,否则在队列为full之前,GUI中的监控进度条与后台下载任务将持续运行至默认TIMEOUT。TIMEOUT可在getpaper/config.py中进行修改
GetPaper 1.0
根据输入的关键词,从选择的数据库中爬取文献的标题、作者、期刊、日期、摘要、doi和网址等信息。
保存按钮可以将爬取到的信息保存至本地。
下载按钮是根据爬取到的doi信息从sci-hub下载文献,但有时会出现http.client.IncompleteRead导致文献无法下载,与个人网络情况有关。
后续改进计划
优化爬取结果的表现方法
可从结果中选择需要下载的文献
尝试增加其他数据库
使用多线程提高文献信息获取速度
v1.0下载地址
- pyinstaller打包后的exe文件大小为27M,保存在百度网盘提取码:0u7n。

